Orion 설치
필수 사항
- Python 3.8, 3.9, 3.10, 또는 3.11
- TensorFlow 2.2 이상, 2.15 미만
- NumPy 1.17.5 이상, 2 미만
- pandas 1 이상, 3 미만
권고 사항
- matplotlib
설치 방법
 아나콘다를 검색하여 처음에 뜨는 사이트 접속
아나콘다를 검색하여 처음에 뜨는 사이트 접속
 우측 상단에 Free Download 클릭
우측 상단에 Free Download 클릭
 로그인 창 하단에 작은 글자로 Skip registration 클릭
로그인 창 하단에 작은 글자로 Skip registration 클릭
 각자의 기종에 맞추어 다운로드
각자의 기종에 맞추어 다운로드
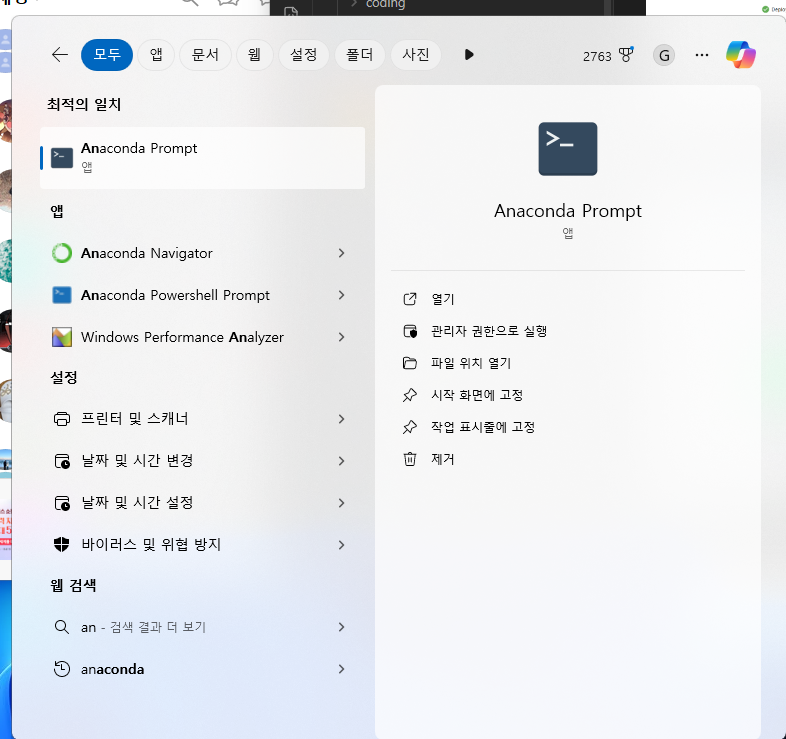 검색 창에 Anaconda Prompt 검색 후 클릭
검색 창에 Anaconda Prompt 검색 후 클릭
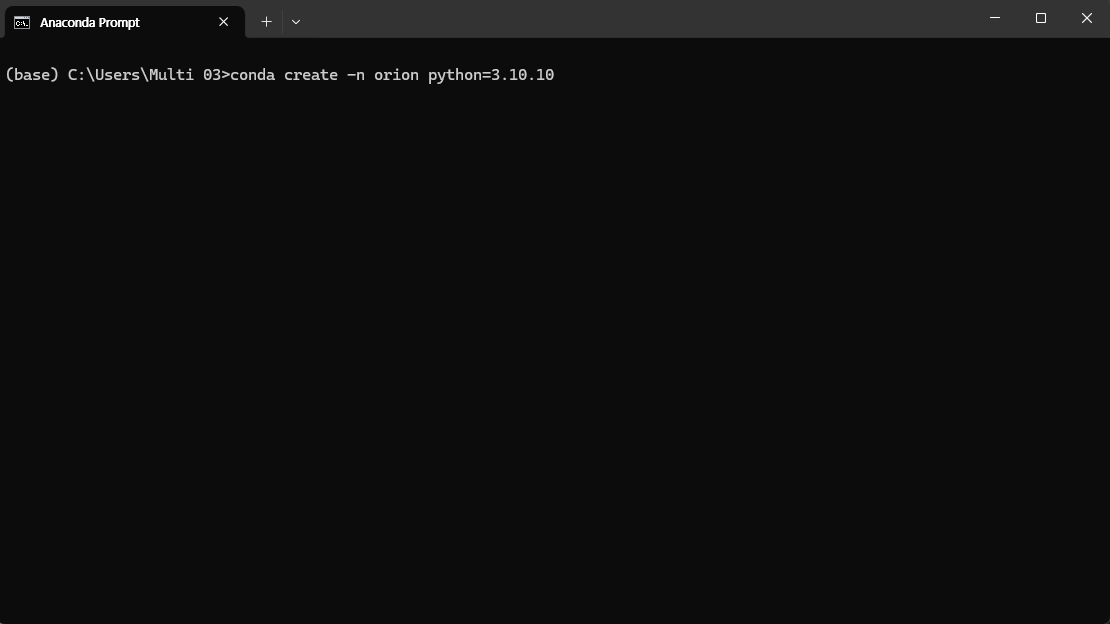
conda create -n (원하는 가상 환경 이름) python=3.10.10
위의 명령어를 통해 가상 환경 설치 및 파이썬 버전 설정
가상 환경의 이름은 원하는 이름으로 하면 되며, 버전은 위에서 언급한 버전에 해당하면, 모두 가능
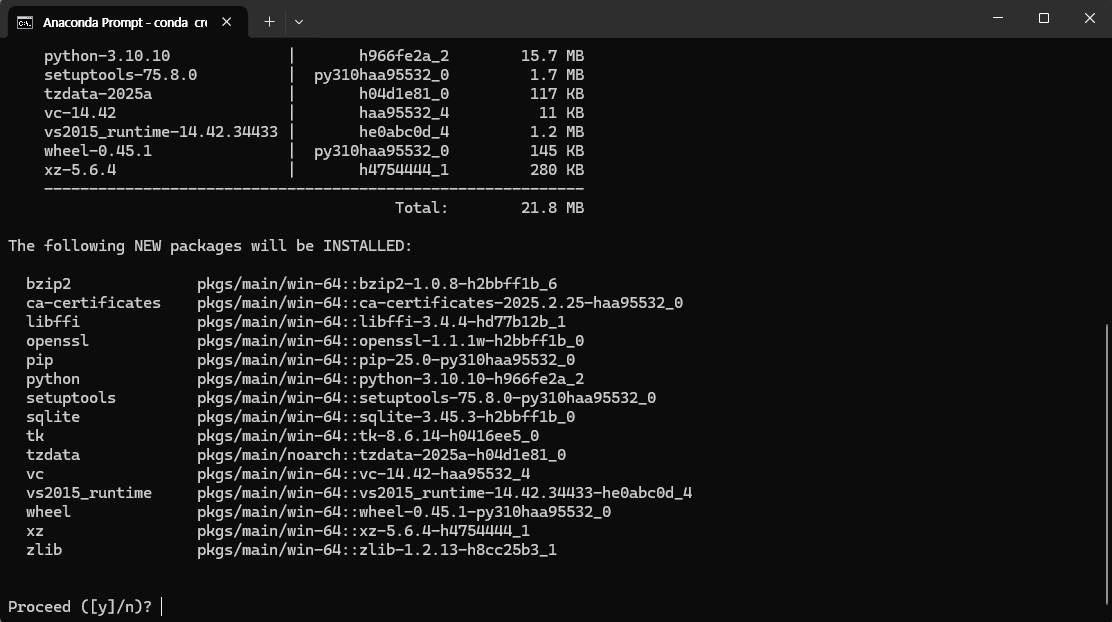 y 입력
y 입력
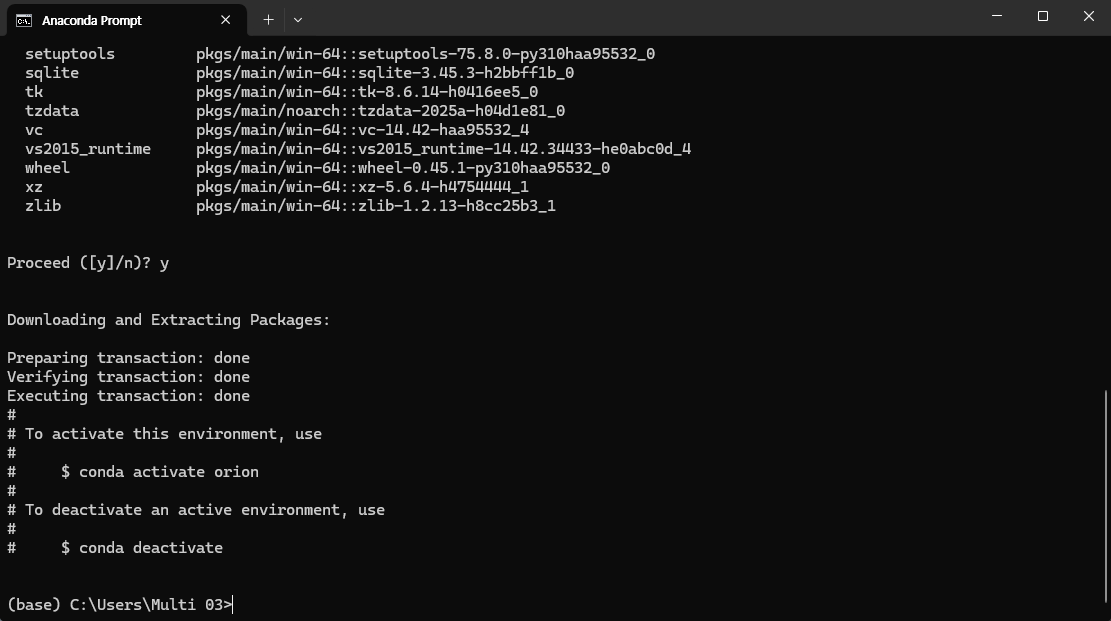 이 화면이 뜨면 계속하여 진행
이 화면이 뜨면 계속하여 진행
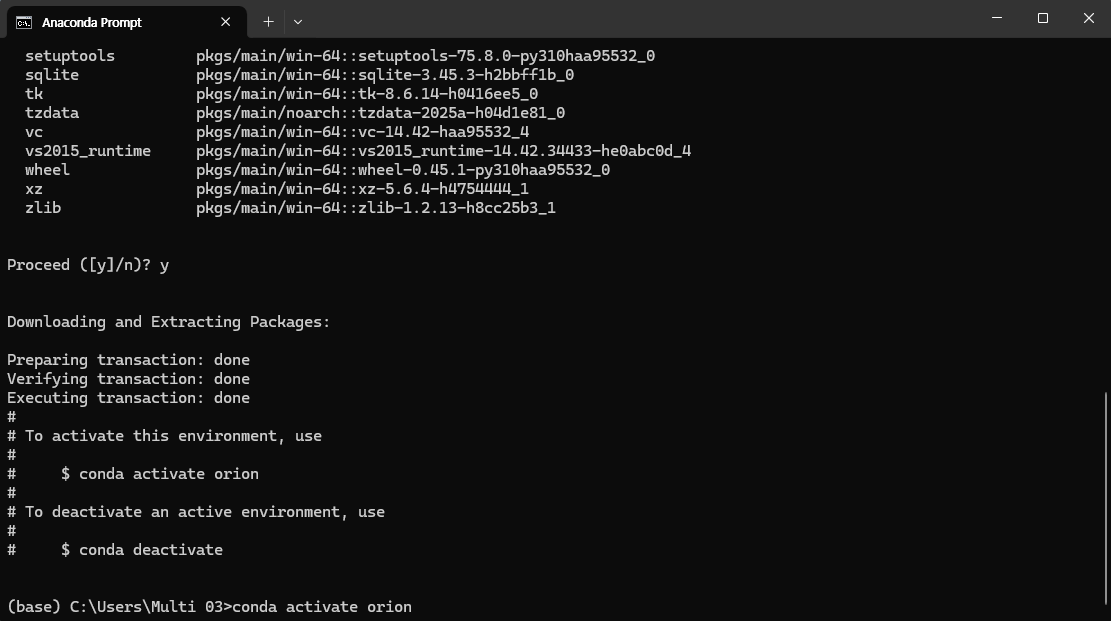
conda activate (가상 환경 이름)
위의 명령어를 통하여 가상 환경 실행
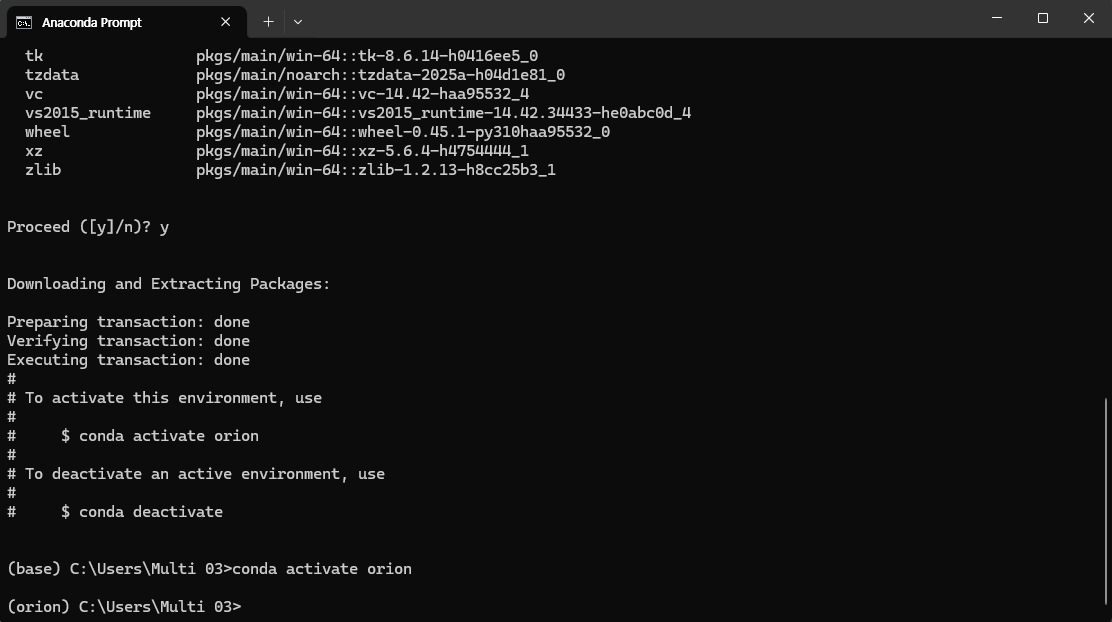 성공 시 base(컴퓨터 환경)에서 (가상 환경 이름)으로 변경 된 것을 알 수 있다.
성공 시 base(컴퓨터 환경)에서 (가상 환경 이름)으로 변경 된 것을 알 수 있다.
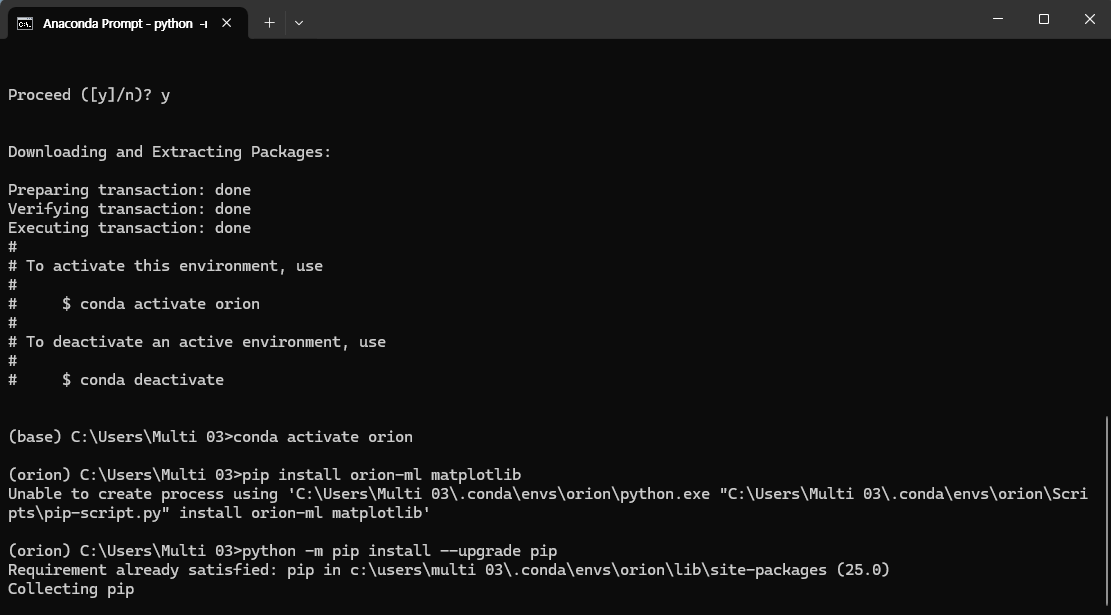
python -m pip install —upgrade pip
위의 명령어를 통해 pip 버전을 올려준다.
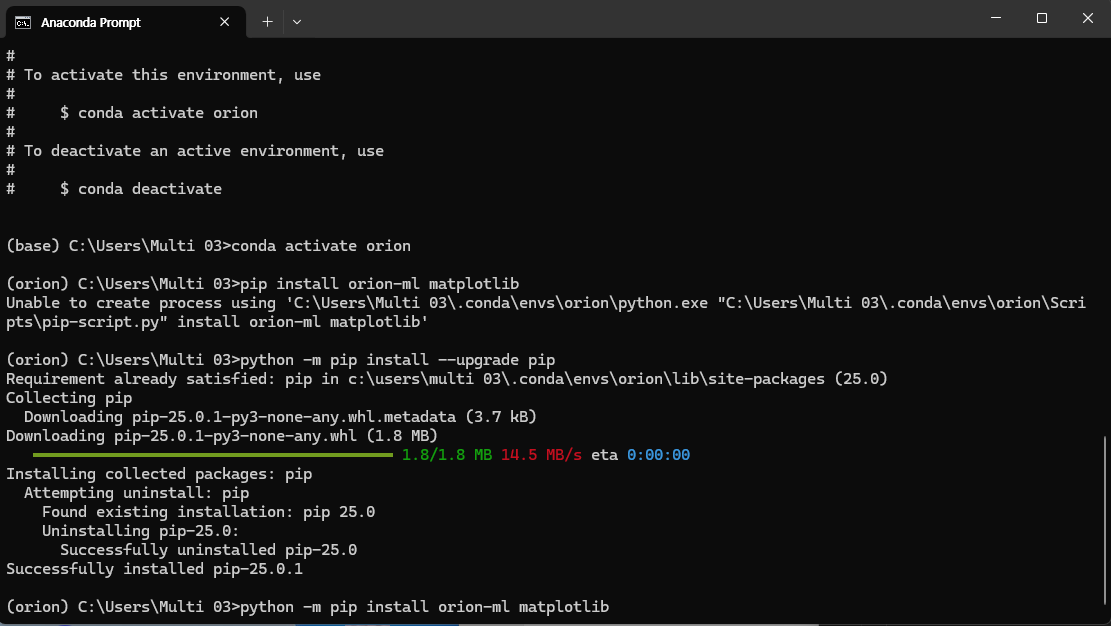
python -m pip install orion-ml matplotlib
위의 명령어를 통해 orion만이 아닌 orion-ml을 설치 함으로써 tensorflow와 numpy, pandas, scikit-learn등 필수적인 패키지를 모두 설치 할 수 있다.
추가로 그래프를 그리기 위한 matplotlib을 설치해 준다.
이 과정에서 3~5분 가량의 시간이 소모될 수 있으니 기다리면 된다.
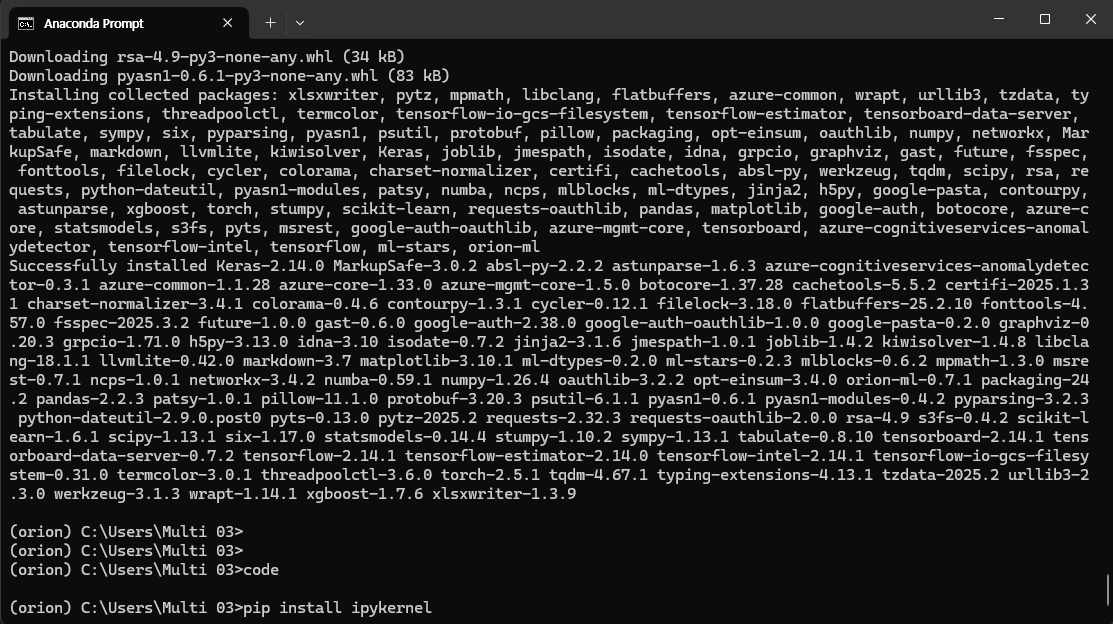
pip install ipykernel
다시 cmd창으로 돌아와 위의 명령어를 입력하자
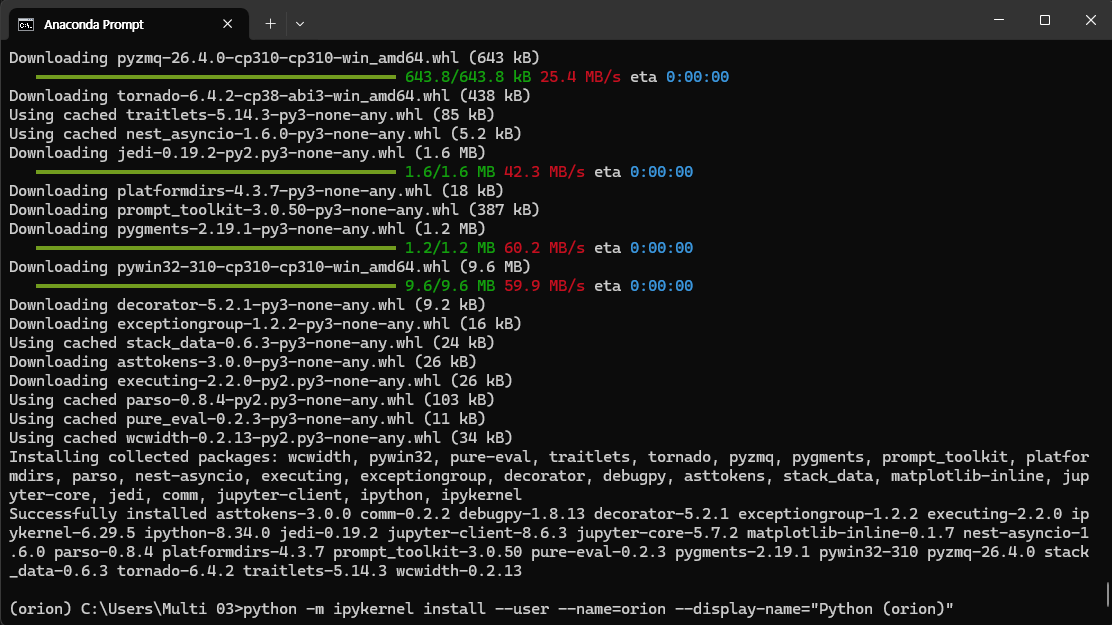
python -m ipykernel install —user —name=orion —display-name=“Python (orion)”
다음 명령어를 통해 가상 환경을 커널에 등록하였다.
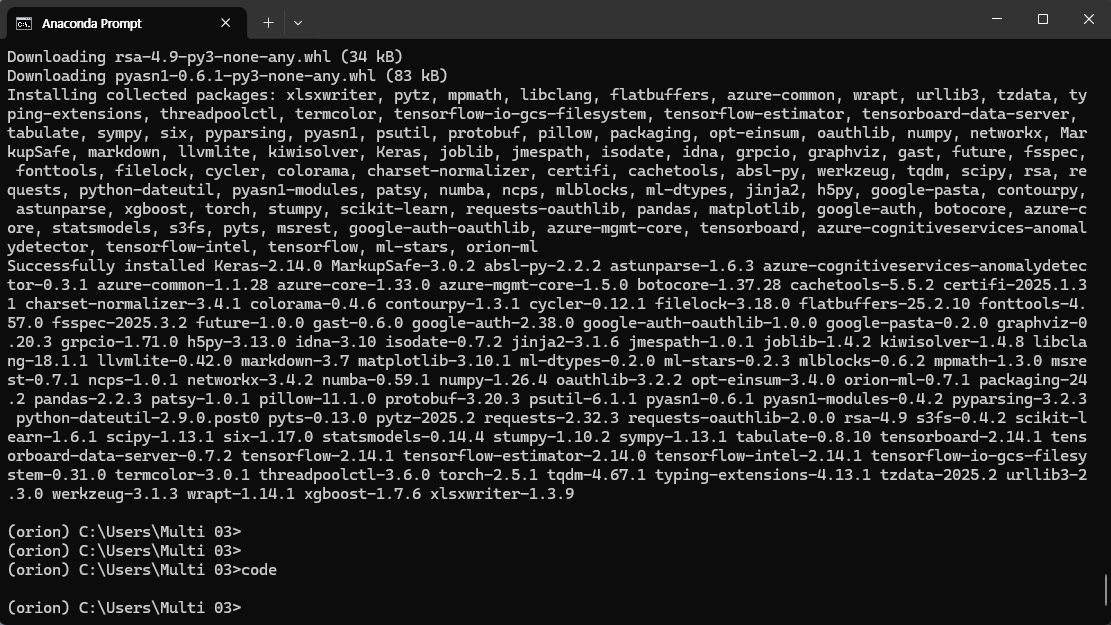
code .
위의 명령어를 실행시키면 다음과 같은 화면을 볼 수 있을 것이다.
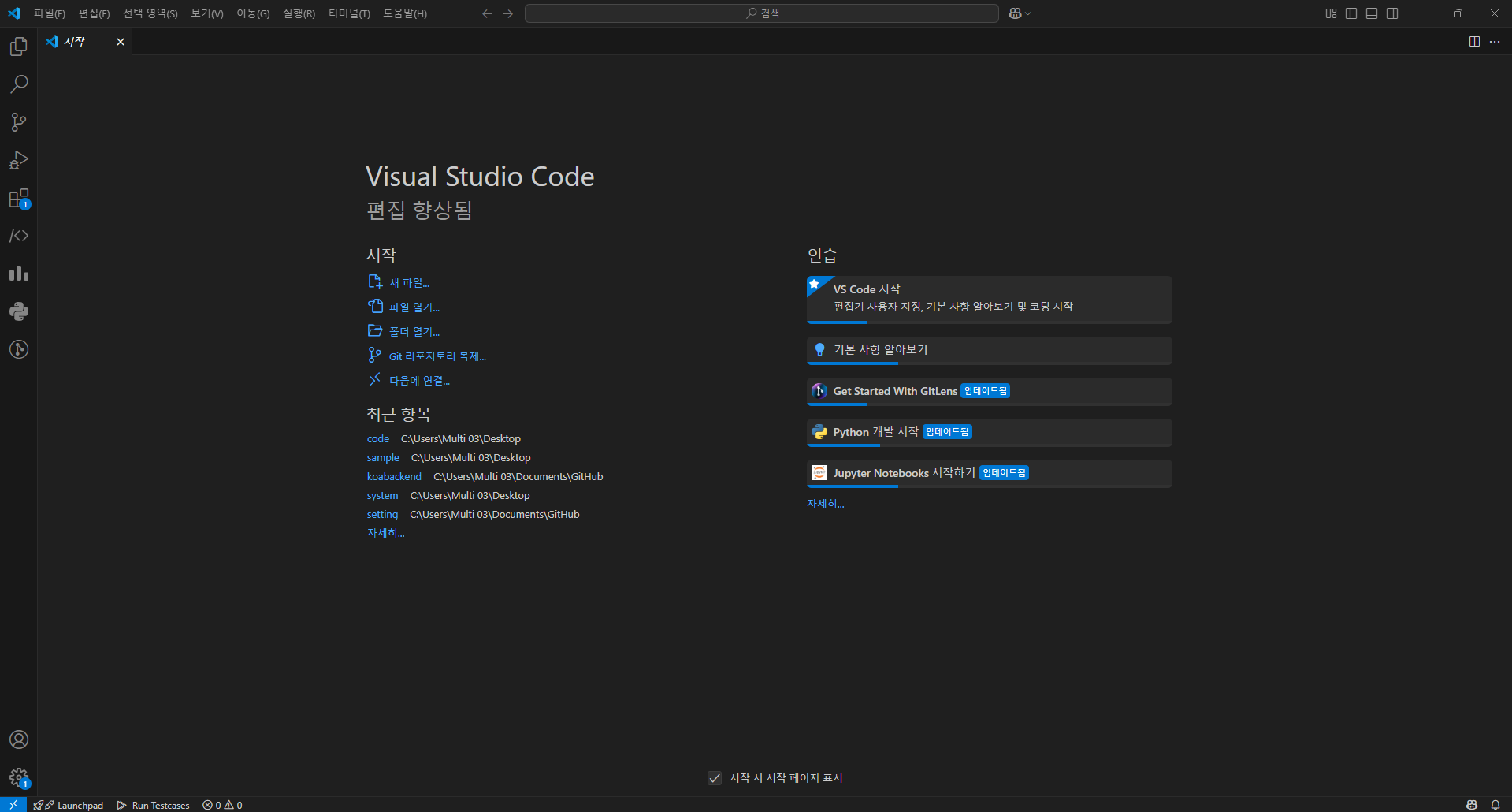 해당 화면이 뜬다면 정상 동작한 것이다.
해당 화면이 뜬다면 정상 동작한 것이다.
 폴더 열기를 통해 본인이 파일을 저장할 폴더를 연다.
폴더 열기를 통해 본인이 파일을 저장할 폴더를 연다.
 적당한 이름의 ipynb파일을 생성한다.
적당한 이름의 ipynb파일을 생성한다.
 우측 상단을 보면 현재 환경이 python일 것인데 이를 클릭하여 아까 만든 가상 환경으로 전환한다.
우측 상단을 보면 현재 환경이 python일 것인데 이를 클릭하여 아까 만든 가상 환경으로 전환한다.
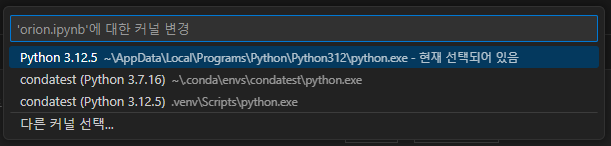 우측 상단의 커널을 누르면 다음과 같은 화면이 나올 것이다. 여기서 다른 커널 선택을 누른다.
우측 상단의 커널을 누르면 다음과 같은 화면이 나올 것이다. 여기서 다른 커널 선택을 누른다.
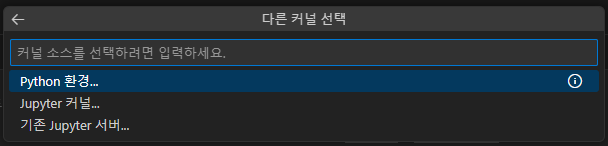 그 후 Python 환경을 누른다.
그 후 Python 환경을 누른다.
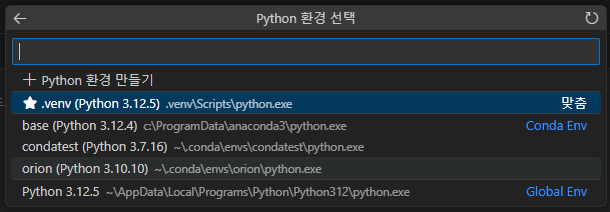 그러면 새로 만든 orion 가상 환경이 설치 되어있는 것을 알 수 있다.
그러면 새로 만든 orion 가상 환경이 설치 되어있는 것을 알 수 있다.
다음은 예제 코드이다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from orion import Orion사용할 라이브러리들을 호출해준다.
pandas는 엑셀등의 파일을 읽거나 쓸 거나, 데이터의 포멧을 바꿀 때 사용된다. numpy는 더욱 뛰어난 배열을 사용하기 위해 사용하였다. pyplot은 matlabb의 그래프를 그리기 위해 사용하였다. 마지막으로 orion은 lstm으로 데이터를 분석하기 위해 사용하였다.
timestamps = np.arange(1000)
values = np.sin(timestamps * 0.1) + np.random.normal(0, 0.1, 1000)해당 부분은 sine 파형의 데이터를 임의로 생성하기 위해 사용하였다.
np.arange(1000)는 0~999까지의 정수 배열을 만들기 위해 사용하였다. np.sin(timestamps * 0.1)는 timestamps * 0.1를 x값으로 sine파형을 만들기 위해 사용하였다.
np.random.normal(0, 0.1, 1000)을 통해 0~999까지 랜덤하게 표준편차가 0.1이 되도록 데이터에 노이즈를 주기 위해 사용하였다.
values[800:810] += 2.0
values[600:630] -= 1.5데이터에 오류 값을 만들기 위해
800810 부분에는 급증 이상치를
600630 부분에는 급감 이상치를
만들어 주었다.
data = pd.DataFrame([
'timestamp': timestamps.astype(np.int64),
'value': values.astype('float32')
})데이터를 학습 시킬 수 있는 형태로 정규화 하기 위한 코드이다.
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams['axes.unicode_minus'] =False출력 가능한 한국어 폰트로 바꾸어 주기 위한 코드이다.
plt.figure(figsize=(12, 6))
plt.plot(data['timestamp'], data['value'])
plt.title('이상치가 포함된 합성 시계열')
plt.xlabel('타임스탬프')
plt.ylabel('값')
plt.show()pyplot를 사용하여 그래프를 출력하는 부분이다.
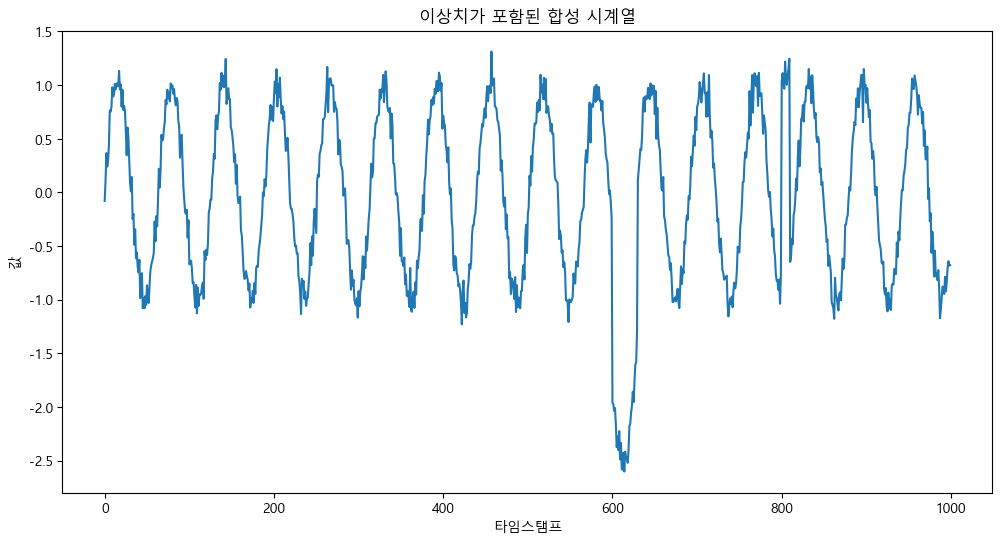 출력한 값은 다음과 같다.
출력한 값은 다음과 같다.
hyperparameters = {
"mlstars.custom.timeseries_preprocessing.time_segments_aggregate#1": {
"interval": 1,
"time_column": "timestamp",
},
"mlstars.custom.timeseries_preprocessing.rolling_window_sequences#1": {
"target_column": 0,
"window_size": 50,
"target_size": 1
},
"orion.primitives.tadgan.TadGAN#1": {
"epochs": 10,
"batch_size": 32,
"verbose": True
},
"orion.primitives.timeseries_anomalies.find_anomalies#1": {
"window_size_portion": 0.15,
"min_percent": 0.3,
"anomaly_padding": 0,
"lower_threshold": False,
"fixed_threshold": False
}
}다음은 하이퍼 파라미터이다.
- mlstars.custom.timeseries_preprocessing.time_segments_aggregate#1
시간 세그먼트를 집계하는 전처리 단계를 뜻함
- interval : 데이터를 집계할 시간 간격 (예: 1시간, 1일 등)
- time_column : 집계에 사용할 타임스탬프 컬럼
- mlstars.custom.timeseries_preprocessing.rolling_window_sequences#1
시계열 데이터에 대해서 슬라이딩 윈도우 방식으로 시퀀스를 생성하기 위해 사용
- target_column : 대상 컬럼 인덱스
- window_size : 각 시퀀스의 길이
- target_size : 예측할 타겟의 크기
- orion.primitives.tadgan.TadGAN#1
시계열 이상 탐지를 위한 TadGAN을 사용
- epochs : 학습 반복 횟수
- batch_size : 한 번에 처리할 데이터 묶음 크기
- verbose : 학습 과정 상세 로그 출력 여부
- orion.primitives.timeseries_anomalies.find_anomalies#1
학습된 모델 결과를 기반으로 실제 이상치 탐지하기 위해 사용
- window_size_portion : 윈도우 크기의 비율
- min_percent : 최소 이상치 비율
- anomaly_padding : 이상치 주변 패딩 크기
- lower_threshold : 낮은 임계값 사용 여부
- fixed_threshold : 고정 임계값 사용 여부
orion = Orion(pipeline='tadgan', hyperparameters=hyperparameters)다음은 orion의 파이프라인으로 tadgan, 즉 Time series Anomaly Detection GAN,을 사용하여 데이터를 분석하기 위해 사용하였다.
TadGAN은 이름대로 시계열 데이터 이상 탐지용 GAN 모델이다. LSTM Auto Encoder와 비슷한 역할을 하며, 데이터 포멧을 만들기에 LSTM 보다 쉽기에 해당 파이프라인을 사용하였다.
파이프라인은 데이터가 순차적인 흐름으로 처리과정이 진행되는 구조를 말한다.
train_size = 500
train_data = data.iloc[:train_size].copy()
test_data = data.iloc[train_size:].copy()이전에 코드를 보면 600630, 800810 구간에 이상치를 만들었다. 즉 500이전에는 이상치가 존재하지 않는다는 것이다.
그럼으로 500 이전까지의 데이터로 학습을 하며, 500 이후의 데이터를 분석하기 위해 데이터를 훈련 데이터와 테스트 데이터로 나눈 모습이다.
orion.fit(train_data)위의 코드를 통해 지정했던 파이프라인과 하이퍼 파라미터로 학습을 진행한다.
anomalies = orion.detect(test_data)그 후 해당 부분을 통해 테스트 데이터를 검사한다.
plt.figure(figsize=(12, 6))
plt.plot(test_data['timestamp'], test_data['value'], label='시계열')
if not anomalies.empty:
for _, anomaly in anomalies.iterrows():
plt.axvspan(anomaly['start'], anomaly['end'], color='red', alpha=0.3)
plt.title('TadGAN로 탐지된 이상치가 표시된 시계열')
plt.xlabel('타임스탬프')
plt.ylabel('값')
plt.legend()
plt.show()그 후 이상치가 감지 된 부분에 빨간색으로 칠한후 plot 해주면 다음과 같은 결과 값을 가질 수 있다.
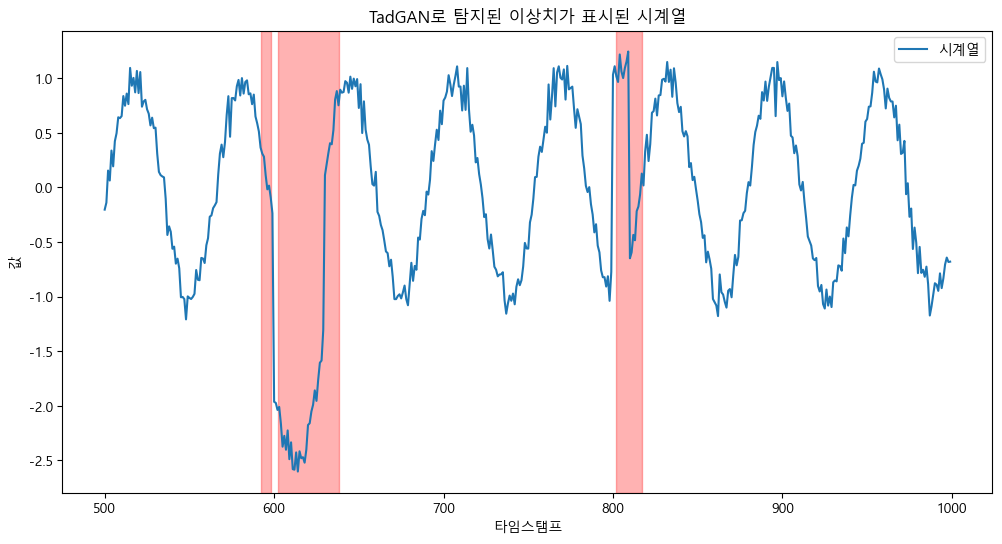 살짝 오류가 있으나, 전체적으로 이상치를 잘 잡아낸 모습이다.
살짝 오류가 있으나, 전체적으로 이상치를 잘 잡아낸 모습이다.
만일 하이퍼파라미터의 값을 변화시킨다면 어떻게 될까?
hyperparameters = {
"mlstars.custom.timeseries_preprocessing.time_segments_aggregate#1": {
"interval": 1,
"time_column": "timestamp",
},
"mlstars.custom.timeseries_preprocessing.rolling_window_sequences#1": {
"target_column": 0,
"window_size": 50,
"target_size": 1
},
"orion.primitives.tadgan.TadGAN#1": {
"epochs": 10,
"batch_size": 32,
"verbose": True
},
"orion.primitives.timeseries_anomalies.find_anomalies#1": {
"window_size_portion": 0.1,
"min_percent": 0.15,
"lower_threshold": False,
"fixed_threshold": False
}
}이상치 검출 부분을 빡빡하게 바꾸어 보았다.
윈도우의 크기를 0.15 에서 0.1로 최소 이상치 비율을 0.3에서 0.15로
변경 하였을 때, 다음과 같은 결과를 확인할 수 있다
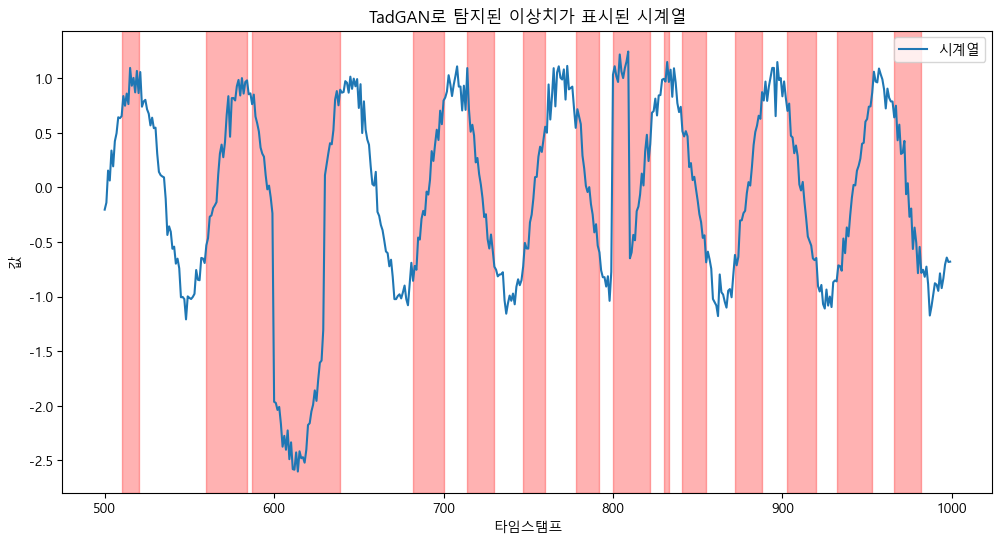 너무 파라미터의 값을 빡빡히 잡아도 모델의 감도를 지나치게 뛰어나게 만들어 적당히 설정하는 것이 중요하다.
너무 파라미터의 값을 빡빡히 잡아도 모델의 감도를 지나치게 뛰어나게 만들어 적당히 설정하는 것이 중요하다.